
Syngenta: Steam consumption optimization
Reliable strategies to save energy in Syngenta’s Kaisten plant

Abstract
This project, conducted by the Swiss Data Science Center (SDSC) in collaboration with Syngenta, aimed to improve the energy efficiency of industrial distillation columns by reducing steam consumption while maintaining required product quality and throughput. The work focused on two main distillation columns (K21 and K521) and combined advanced machine learning with mathematical and statistical optimization to identify optimal operating strategies.
People
Collaborators

Dan received an MSc in civil and environmental engineering from UC Berkeley and a Ph.D. from EPFL, where he developed models combining machine learning and geographic information systems to estimate renewable energy potentials on a large scale. After serving as a researcher/data scientist at Unisanté (Lausanne) and completing a one-year postdoc at the Quebec Artificial Intelligence Institute (Mila) in Montréal, Dan joined the SDSC Innovation team. His work has generally been focusing on crafting and tailoring machine learning methods and deep learning architectures for a variety of domains, most notably the spatio-temporal modeling and forecasting of environmental and energy related variables, as well as multiple applications in public health research.

Matthias Galipaud obtained his PhD in evolutionary biology in 2012 from the University of Burgundy in Dijon (France), and held postdoctoral positions as a mathematical biologist at the university of Bielefeld (Germany) and the university of Zurich, where he researched the evolutionary theories of aging and mate choice. In 2020, he became a data scientist, developing machine learning solutions for startups in Switzerland and Australia before joining the SDSC Innovation Team in November 2022.

Saurabh Bhargava, joined the SDSC as a Principal Data Scientist in the Industry Cell at the Zürich office in 2022. Saurabh previously worked in the retail sector and the advertising industry in Germany. He lead and built various data products for customers using state of the art machine learning methods and industrializing them thereby adding value for the customers. He completed his PhD from ETH Zürich in June 2017 specializing in machine learning applications on Audio data. He obtained his Master’s and Bachelor’s degrees from EPFL and Indian Institute of Technology (IIT), Roorkee, India in 2011 and 2009 respectively. His interests and expertise are in combining state of the art data science and data engineering tools for building scalable data products.
description
Objectives
• Develop a reliable predictive model for steam consumption based on historical process data at the chemical plant site in Kaisten, Switzerland.
• Identify operational levers influencing steam efficiency.
• Optimize distillation column feed strategies to minimize steam usage while meeting production targets.
• Provide actionable recommendations and tools to plant operators.
Approach
The project was executed in two main steps, combining data-driven modeling with prescriptive optimization.
Step 1 — Steam Prediction Model
We first developed a reliable simulation of column steam consumption. After exploratory analysis and unsuccessful attempts at purely physics-based simulation using PID-controller logic, we adopted an AI-based time-series forecasting model to predict short-term steam consumption from historical process signals.
Transformer-based models were trained for each distillation column, using time series of historical data (feed, water, reflux ratio, and cross-column interactions capturing heat recovery effects). The model achieved strong predictive performance on unseen data, with R² ≈ 0.95 for either column (Figure 1). To enable fast optimization, distilled neural network surrogate models were later trained to approximate the transformers with significantly lower computational cost while preserving high predictive performance.

Step 2 — Optimization Model
Using the steam prediction model as a digital surrogate of the plant’ distillation process, we formulated an optimization problem to find feed strategies that minimize total weekly steam consumption while satisfying:
• Production targets (e.g., weekly end product demand)
• Operational constraints (feed bounds, tanks capacity limits, operators preference)
Two complementary optimization methods were evaluated:
• Linear Programming (LP) — exact optimization after linearization of the steam model.
• Genetic Algorithms (GA) — flexible statistical optimization without linearity assumptions.
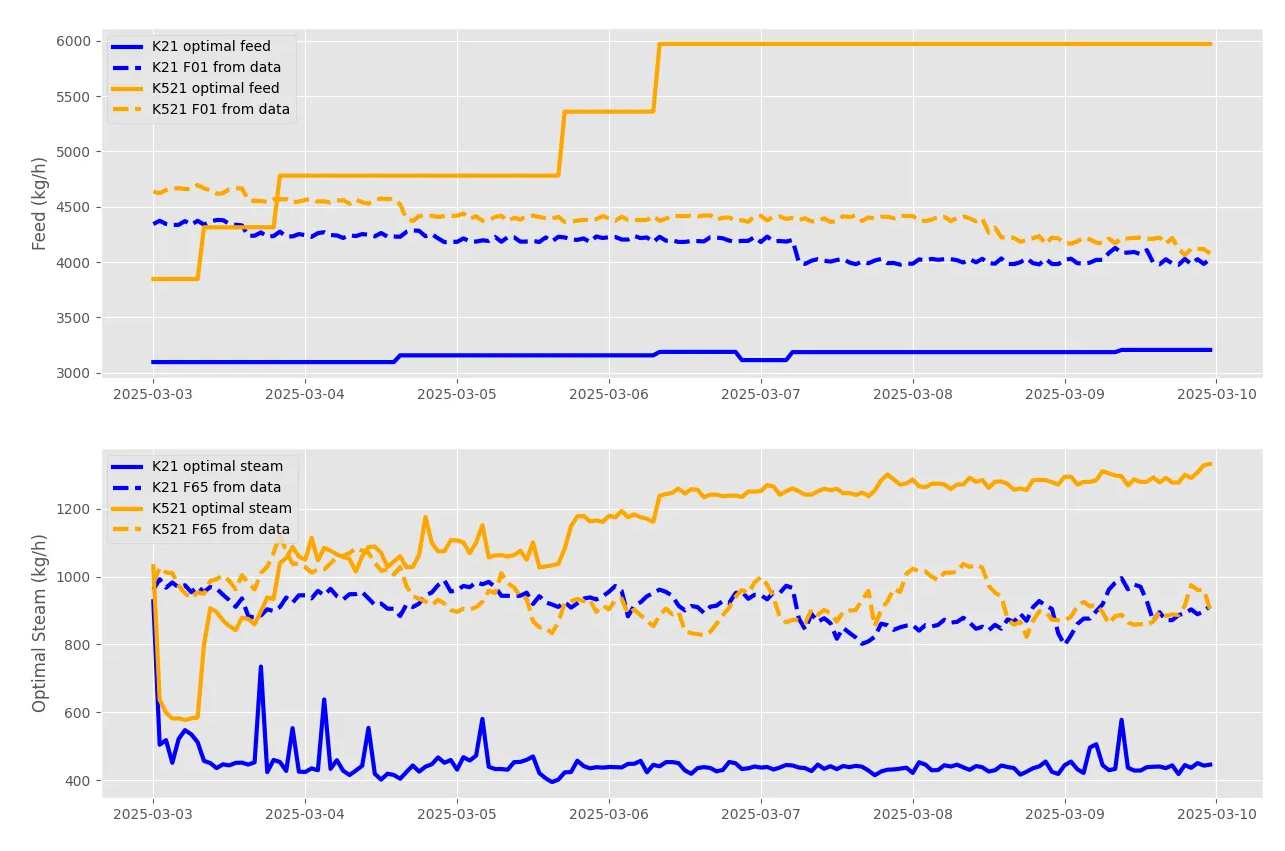
The LP approach provided theoretically optimal solutions under defined constraints (Figure 2), while GA offered robust alternatives for highly non-linear scenarios.
Key Findings
• Heat recovery interactions between distillation columns significantly impact efficiency.
• Operating both columns together is generally more energy efficient.
• The AI steam model can reliably evaluate candidate operating strategies.
• Optimization reveals consistent over-steaming in historical operations, indicating real savings potential.
Impact
On representative test weeks, the optimized strategies achieved meaningful steam reductions while meeting production requirements. For example, during the example week in Figure 2 (March 3rd–10th, 2025), the optimized plan reduced steam usage from 312 tons to 268 tons, a saving of 44 tons of steam for that week.
Across broader historical simulations, constrained optimization scenarios indicated substantial cumulative savings potential without requiring hardware changes. The work demonstrates that data-driven operational optimization can deliver measurable energy and cost benefits in continuous chemical processes.
Beyond immediate savings, the delivered steam model provides Syngenta with a reusable digital capability to:
• Evaluate future operating strategies offline
• Support operator decision-making
• Enable future closed-loop or advisory optimization systems.
Future Opportunities
• Extend modeling to product quality prediction.
• Incorporate forecasts of stochastic inputs (tank inflow, disturbances).
• Deploy decision-support tools for operators.
• Explore real-time optimization integration.
The project establishes a strong foundation for AI-driven process optimization at scale.
Presentation
Gallery
Annexe
Additional resources
Bibliography
Publications
More projects
CHUV: Heracles - Sepsis Model

AI-Driven Political Monitoring

LUCID National Data Stream

Canton de Vaud: ENERBAT
More projects
News
Latest news

Coding the Future: Energy Data Hackdays Expand to French-speaking Switzerland
Coding the Future: Energy Data Hackdays Expand to French-speaking Switzerland

Science des données : le SDSC et le Canton de Vaud soutiennent quatre projets appliqués
Science des données : le SDSC et le Canton de Vaud soutiennent quatre projets appliqués

Le Swiss Data Science Center inaugure son siège au Biopôle de Lausanne
Le Swiss Data Science Center inaugure son siège au Biopôle de Lausanne
Contact us
Let’s talk Data Science
Do you need our services or expertise?
Contact us for your next Data Science project!